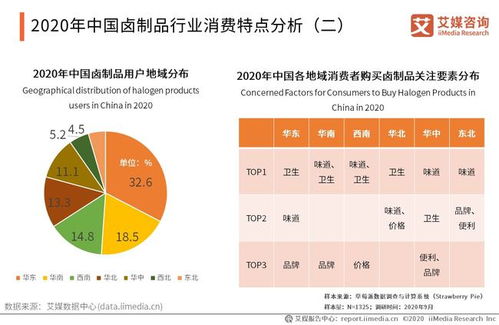
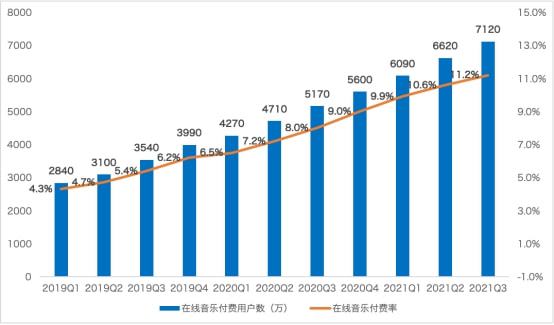
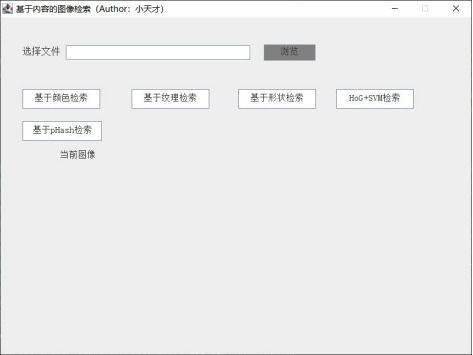
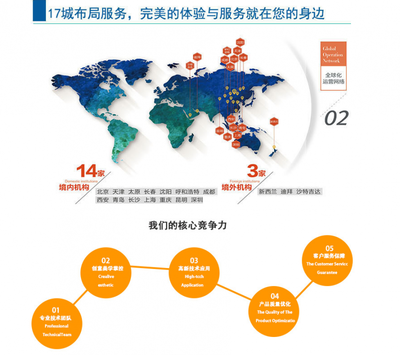
卓特视觉携手豆包大模型 AI大模型赋能,开启版权内容智能化新时代

在数字内容产业高速发展的今天,内容创作、管理与分发的效率与智能化水平,已成为行业竞争的核心要素。领先的数字内容制作服务商卓特视觉与前沿的豆包大模型达成深度合作,共同宣布以AI大模型技术深度赋能版权内容生态,标志着数字内容制作服务正式迈入智能化赋能的新纪元。
这一战略合作的核心,在于将豆包大模型强大的多模态理解、生成与推理能力,无缝接入卓特视觉庞大的高质量版权内容库与全流程制作服务体系。对于内容创作者而言,这意味着革命性的体验升级。过去,在海量图库中精准寻找符合创意构思的素材,往往需要耗费大量时间与精力。现在,通过自然语言描述,AI能够瞬间理解“落日余晖下都市剪影的科技感”或“体现家庭温馨的互动场景”等复杂需求,从数以亿计的视觉资产中精准筛选、推荐甚至进行智能组合与初步编辑,极大提升了创意发想与素材获取的效率。
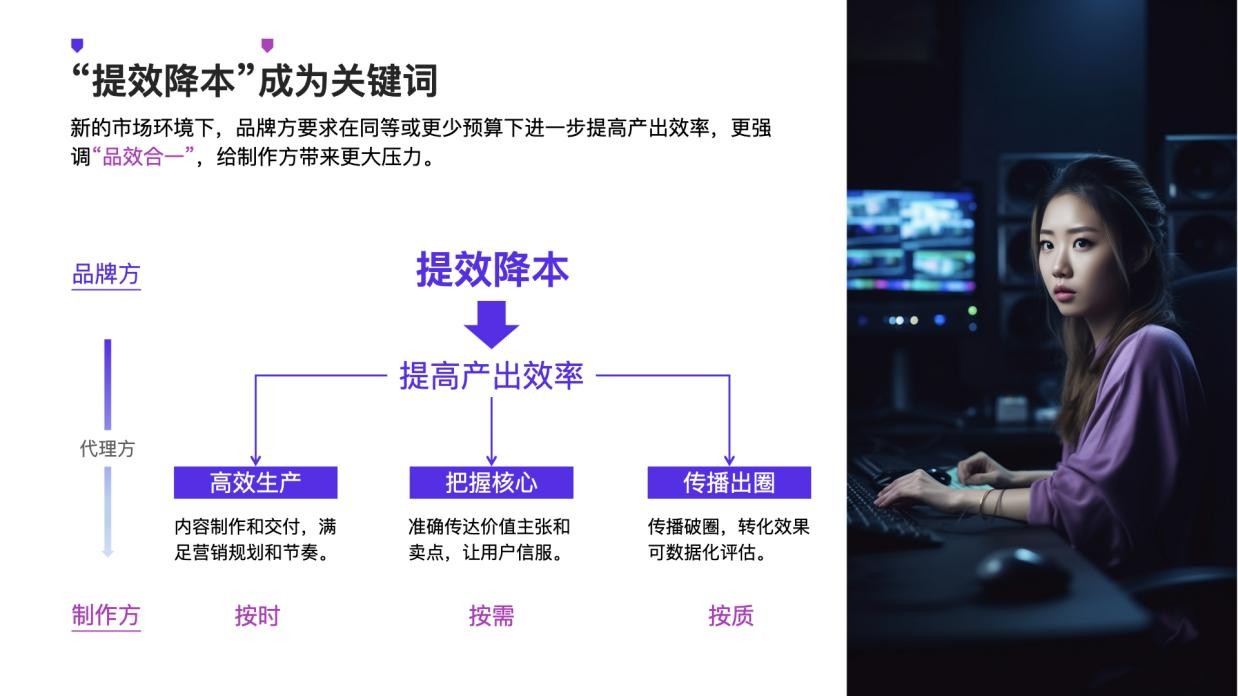
不仅如此,在内容生产环节,AI大模型的赋能将不止于搜索。它可以协助完成智能修图、风格迁移、元素扩展、场景生成等任务,让专业级视觉内容的定制与批量化生产成为可能。对于视频内容,AI能辅助完成脚本创意、智能剪辑、字幕生成乃至部分特效处理,缩短制作周期,降低技术门槛。卓特视觉凭借其深厚的行业经验与质量控制体系,确保AI生成与处理的内容在创意、合规与版权清晰度上达到商用标准。
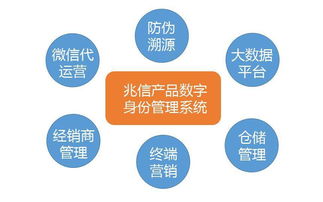
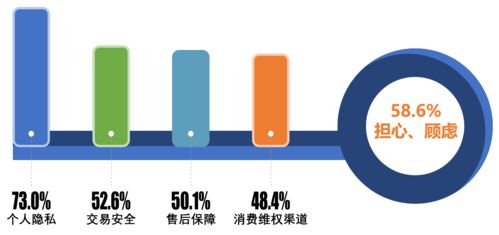
在版权管理与交易层面,智能化变革同样深刻。AI模型能够对入库内容进行更精细化的自动标签、分类与版权信息识别,构建起更智能、更立体的内容知识图谱。这不仅提升了内部资产管理效率,也能为下游客户提供更精准的授权方案与风险提示。基于大模型的数据分析能力,卓特视觉可以更精准地洞察市场趋势与用户偏好,反哺内容创作与引进策略,形成“数据驱动创作、智能赋能交易”的良性循环。
卓特视觉与豆包大模型的此次携手,超越了简单的工具应用,是一次对数字内容产业底层工作流的重塑。它预示着,未来的数字内容服务将不再是简单的素材提供,而是融入了智能创意、智能生产、智能管理与智能交付的一站式解决方案。版权内容的真正价值,将在AI的赋能下得到前所未有的释放与延展。
可以预见,随着AI大模型技术的持续演进与行业应用的深入,一个更加高效、智能、充满创意的数字内容新时代已经开启。卓特视觉正站在这一浪潮的前沿,通过智能化升级,致力于为全球的企业、媒体与创作者提供更强大、更可靠的内容引擎,共同绘制数字视觉经济的全新版图。
如若转载,请注明出处:http://www.houwangzn.com/product/57.html
更新时间:2026-01-12 19:23:04